
Chief Executive Officer
Published: August 1, 2025

AI-enhanced fraud is advancing so rapidly that what once felt like science fiction is now disrupting boardrooms, financial systems, and even governments. And while the cybersecurity industry has responded with deepfake detection tools—powered by AI models trained to identify synthetic voice and video content—the uncomfortable truth is this:
Video deepfake detection alone is not enough to truly know who you’re talking to.
The Problem with Deepfake Detection Alone
Most deepfake detection technologies today focus on visual and audio inconsistencies: things like unnatural blinking patterns, audio-visual desynchronization, or subtle facial distortions. These tools often rely on AI inference models—both supervised and unsupervised—that examine frames and waveforms for anomalies.
While these models are improving, they are far from foolproof:
Many are trained on known deepfakes, making them vulnerable to new zero-day variations
They struggle with compressed video, poor lighting, or low bandwidth calls
And they’re reactive—by the time detection happens, the damage may already be done
In high-stakes environments like enterprise finance, national defense, or executive comms, relying on a model that returns a 73% confidence score isn’t just risky—it’s reckless.
What Does “Really Knowing” Mean?
Let’s step back. When you talk to a colleague, a family member, or a business partner, you don’t “verify” them like a CAPTCHA. You recognize them—automatically, subconsciously, based on hundreds of subtle cues and patterns. The tone of their voice. The time they usually call. The email domain they use. Even their typing rhythm.
That’s not just biometrics. That’s metadata—and it’s far more powerful than any single deepfake detection tool.
Why Metadata Is the Missing Link
At Netarx, we believe deepfake detection is just one layer in a broader shared awareness model. That’s why we built the Netarx Identity Key—a platform that aggregates metadata from dozens of communication sources and feeds them into an ensemble of AI models.
Here’s how it works:
A voice call from an executive comes in at 2:15am from Nigeria—your team’s never received one at that hour from that region.
A video chat is requested from someone who just messaged you from a VPN IP used by known phishing actors.
A familiar face appears on video—but the GPS metadata and device signature don’t match prior patterns.
Each of these signals may be small. But combined, they tell a story—and often a much clearer one than the pixels in a manipulated video.
Ensemble Models > Video Alone
The Netarx Identity Key platform uses over 50 metadata features—from geolocation to time-of-day patterns, to device fingerprints, to language analysis. These inputs are evaluated across supervised learning, unsupervised anomaly detection, and a voting ensemble model.
In practical terms: it doesn’t just ask, “Does this look fake?” It asks:
“Have we seen this behavior before?”
“Does this feel familiar?”
“Is this person acting like themselves?”
That’s not detection. That’s recognition.
Trust Shouldn’t Be Assumed—or Required
In a world that started with “zero trust,” the next evolution is recognizing that no trust is required when you have true shared awareness. With the right metadata, you don’t have to guess. You know.
AI-enhanced fraud won’t be beaten by better video filters alone. It will be beaten by context, correlation, and collective awareness. And that’s the mission of Netarx Identity Key : to make synthetic deception not just detectable—but unconvincing.

Chief Executive Officer
CEO/Founder of Netarx LLC, Real-time detection of deepfake and social engineering threats via enterprise video, voice and email. Managing Partner of Koach Capital, a Private Equity firm managing a multitude of commercial real estate (CRE) funds whose focus is retail sale-leasebacks. Sandy's entrepreneurial success began by founding a network integration and services provider that served large enterprises. We focused on advanced technologies including Business Intelligence (BI), Network & Information Security, Virtualization, Storage Area Networks, Unified Communications and Data Center Services. In 2009, Netarx acquired the VAR business of Analysts International (including Sequoia and Entree Systems). In 2011 Netarx was acquired by Logicalis (a division of Datatec - Symbol LSE: DTC) and stayed on as its Chief Technology Officer. He continued to build by founding Verge.io (Formerly Yottabyte) and Service.com. Also, Sandy served as a General Partner of Ludlow Ventures, a venture capital fund focusing on investments in early-stage tech companies. Sandy contributes to the community via lectures, publications and developing new technologies - he currently holds 8 Patents.

blog
Human defense is the discipline of protecting people, not just systems, from social engineering, phishing, and AI-driven impersonation. It combines human risk management (HRM), behavior analytics, and identity controls with the layer most programs are still missing in 2026: live deepfake and impersonation detection across voice, video, and email. Sometimes called human-centric cybersecurity or the human firewall, it turns employees from the weakest link into a continuously verified, actively defended layer.

blog
The 2026 NIST baseline says four things clearly. Voice biometrics can no longer stand alone as a login factor. Presentation Attack Detection has to keep the imposter-accept rate below 0.07. Official media needs verifiable provenance — signed metadata or cryptographic proof of origin. And continuous monitoring plus deepfake-aware drills are now part of normal operations. The publications doing the work are SP 800-63-4, AI 100-4, AI 600-1, and IR 8596.
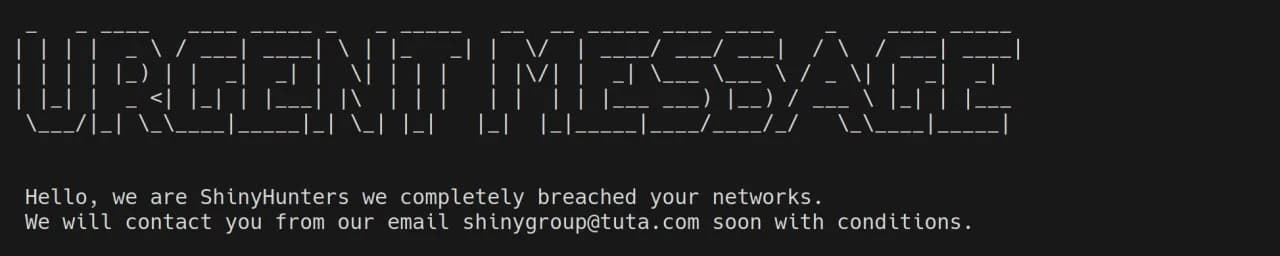
blog
The ShinyHunters data extortion campaign exemplifies a fundamental evolution in cyberattack methodology, exploiting SaaS platforms through identity compromise, advanced social engineering, and bypass of traditional controls. This blog explains how netarx protects against these type of threats.